Paste data.frame rows into a character vector, optionally removing empty fields in order to avoid delimiters being duplicated.
Usage
pasteByRow(
x,
sep = "_",
na.rm = TRUE,
condenseBlanks = TRUE,
includeNames = FALSE,
sepName = ":",
blankGrep = "^[ ]*$",
verbose = FALSE,
...
)Arguments
- x
data.frameor comparable object such asmatrixortibble.- sep
characterstring separator to use between columns.- na.rm
logicalwhether to remove NA values, or include them as"NA"strings.- condenseBlanks
logicalwhether to condense blank or empty values without including an extra delimiter between columns.- includeNames
logicalwhether to include the colname delimited prior to the value, using sepName as the delimiter.- sepName
characterstring relevant whenincludeNames=TRUE, this value becomes the delimiter between name:value.- blankGrep
characterstring used as regular expression pattern ingrep()to recognize blank entries; by default any field containing no text, or only whitespace, is considered a blank entry.- verbose
logicalwhether to print verbose output.- ...
additional arguments are ignored.
Details
This function is intended to paste data.frame (or matrix, or tibble)
values for each row of data.
It differs from using apply(x, 2, paste):
it handles factors without converting to integer factor level numbers.
it also by default removes blank or empty fields, preventing the delimiter from being included multiple times, per the
condenseBlanksargument.it is notably faster than apply, by means of running
paste()on each column of data, making the output vectorized, and scaling rather well for largedata.frameobjects.
The output can also include name:value pairs, which can make the output data more self-describing in some circumstances. That said, the most basic usefulness of this function is to create row labels.
See also
Other jam string functions:
asSize(),
breaksByVector(),
fillBlanks(),
formatInt(),
gsubOrdered(),
gsubs(),
makeNames(),
nameVector(),
nameVectorN(),
padInteger(),
padString(),
pasteByRowOrdered(),
sizeAsNum(),
tcount(),
ucfirst()
Examples
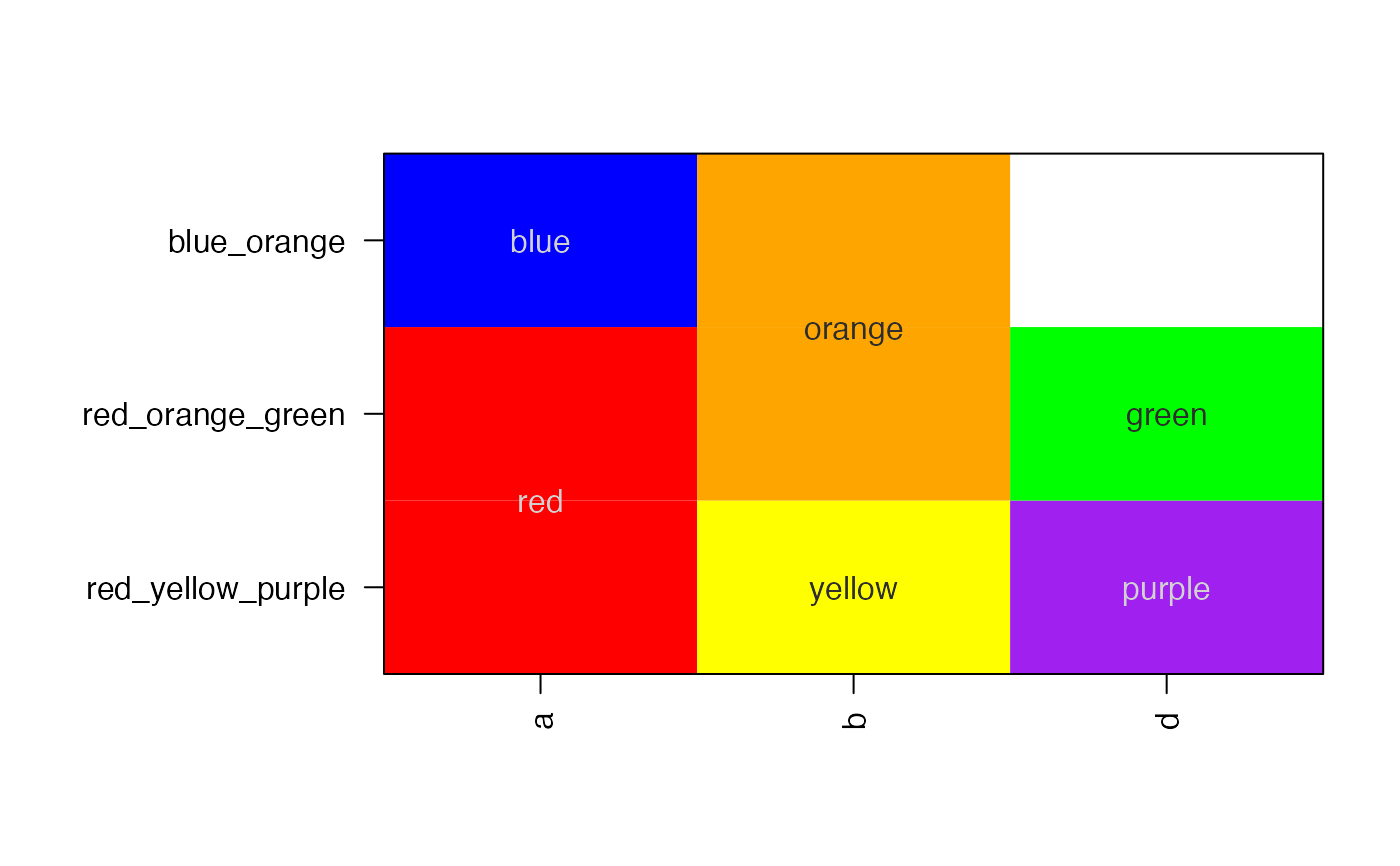
# create an example data.frame
a1 <- c("red","blue")[c(1,1,2)];
b1 <- c("yellow","orange")[c(1,2,2)];
d1 <- c("purple","green")[c(1,2,2)];
df2 <- data.frame(a=a1, b=b1, d=d1);
df2;
#> a b d
#> 1 red yellow purple
#> 2 red orange green
#> 3 blue orange green
# the basic output
pasteByRow(df2);
#> 1 2 3
#> "red_yellow_purple" "red_orange_green" "blue_orange_green"
# Now remove an entry to show the empty field is skipped
df2[3,3] <- "";
pasteByRow(df2);
#> 1 2 3
#> "red_yellow_purple" "red_orange_green" "blue_orange"
# the output tends to make good rownames
rownames(df2) <- pasteByRow(df2);
# since the data.frame contains colors, we display using
# imageByColors()
withr::with_par(list("mar"=c(5,10,4,2)), {
imageByColors(df2, cellnote=df2);
})